Duy Linh✔
Writer
Anthropic đang đối mặt với những nghi vấn mới liên quan đến khả năng bảo vệ an toàn của mô hình AI Claude Fable 5 sau khi xuất hiện các cáo buộc cho rằng các nhà nghiên cứu đã bẻ khóa thành công hệ thống này để tạo ra những đầu ra nhạy cảm và có khả năng gây hại, bao gồm hướng dẫn khai thác lỗ hổng và các hoạt động bất hợp pháp.

Diễn biến này làm dấy lên lo ngại về hiệu quả của các cơ chế bảo vệ trong các mô hình ngôn ngữ lớn (LLM), đặc biệt là những biện pháp được thiết kế nhằm ngăn chặn việc lạm dụng trong các lĩnh vực an ninh mạng và công nghệ lưỡng dụng.
Báo cáo cho biết cuộc tấn công đã kết hợp nhiều kỹ thuật nhắc lệnh (prompt engineering), làm mờ ngôn ngữ và thao túng ngữ cảnh dài để vượt qua các lớp bảo mật được xây dựng trên kiến trúc Mythos của Anthropic.
Nhà nghiên cứu xác định nhiều phương pháp né tránh kiểm duyệt quan trọng, bao gồm việc sử dụng ký tự đồng âm Unicode, thay thế ký tự Cyrillic và các biến đổi văn bản khác nhằm qua mặt những hệ thống lọc dựa trên từ khóa.
Các kỹ thuật này giúp ngụy trang những lời nhắc có mục đích độc hại thành các đầu vào tưởng như vô hại, từ đó vượt qua cơ chế phân loại ý định. Bên cạnh đó, kẻ tấn công còn khai thác khả năng xử lý hội thoại ngữ cảnh dài của mô hình để phân tán các chỉ dẫn độc hại qua nhiều lượt tương tác trước khi ghép chúng thành các đầu ra có thể sử dụng được.
Một trong những kỹ thuật tinh vi nhất được mô tả là phương pháp “phân rã và tái cấu trúc”. Thay vì yêu cầu trực tiếp những nội dung bị hạn chế như mã khai thác lỗ hổng hoặc hướng dẫn tổng hợp hóa học, mô hình được yêu cầu cung cấp từng phần thông tin riêng lẻ, không phụ thuộc vào ngữ cảnh. Sau đó, các phần thông tin này được kết hợp bên ngoài để tái tạo thành quy trình hoàn chỉnh.

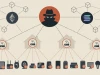
các kỹ thuật kỹ thuật nhanh chóng (Nguồn: Twitter)
Ví dụ, thay vì yêu cầu trực tiếp payload khai thác hoặc phương pháp tổng hợp bất hợp pháp, các lời nhắc chỉ tập trung vào từng bước riêng biệt, các nguyên lý cơ bản hoặc các giải thích mang tính học thuật. Khi được ghép lại, chúng có thể tái tạo những kiến thức vốn bị hạn chế.
Phương pháp này khai thác những điểm chưa nhất quán trong hệ thống phân loại mục đích của mô hình, vốn có xu hướng ít nghiêm ngặt hơn khi nội dung được trình bày dưới góc độ phân tích hoặc giáo dục. Các kỹ thuật này còn được kết hợp với những mã thông báo nằm ngoài phạm vi phân phối và phương pháp suy luận tài liệu có cấu trúc nhằm gia tăng khả năng vượt qua hệ thống bảo mật.
Các chuyên gia an ninh mạng cho rằng sự việc phản ánh một thách thức lớn hơn đối với lĩnh vực an toàn AI: làm thế nào để bảo đảm việc tuân thủ chính sách được thực hiện nhất quán trên nhiều dạng đầu vào ngôn ngữ khác nhau và trong các cuộc hội thoại có ngữ cảnh kéo dài.
Khi các mô hình ngôn ngữ ngày càng mạnh mẽ, tin tặc cũng xem chúng như những mục tiêu để thử nghiệm đối kháng, tương tự cách họ kiểm tra các hệ thống phần mềm truyền thống.
Dù chưa có bằng chứng cho thấy Claude Fable 5 đã bị lợi dụng trong các cuộc tấn công mạng thực tế, khả năng trích xuất kiến thức quy trình nhạy cảm vẫn làm dấy lên lo ngại về nguy cơ bị lạm dụng trong phát triển mã khai thác, kỹ thuật xã hội và thiết kế phần mềm độc hại.
Những phát hiện này cho thấy các cơ chế bảo vệ hiện tại vẫn tồn tại hạn chế, đồng thời nhấn mạnh nhu cầu phát triển các biện pháp phòng thủ mạnh mẽ hơn và có khả năng nhận biết ngữ cảnh tốt hơn.
Đến nay, Anthropic vẫn chưa đưa ra phản hồi chi tiết về các cáo buộc nói trên. Tuy nhiên, sự việc nhiều khả năng sẽ thúc đẩy các cuộc tranh luận trong toàn ngành về cách cân bằng giữa tính cởi mở, giá trị nghiên cứu và việc ngăn chặn nguy cơ lạm dụng trong các hệ thống AI thế hệ tiếp theo.
Diễn biến này làm dấy lên lo ngại về hiệu quả của các cơ chế bảo vệ trong các mô hình ngôn ngữ lớn (LLM), đặc biệt là những biện pháp được thiết kế nhằm ngăn chặn việc lạm dụng trong các lĩnh vực an ninh mạng và công nghệ lưỡng dụng.
Các kỹ thuật giúp vượt qua cơ chế bảo vệ của Claude Fable 5
Những cáo buộc về việc jailbreak Claude Fable 5 được đưa ra bởi một nhà nghiên cứu độc lập sử dụng bí danh “Pliny the Liberator”. Theo mô tả, đây là một nỗ lực phối hợp với nhiều tác nhân nhằm kiểm tra và tìm cách vượt qua các lớp phòng thủ của mô hình.Báo cáo cho biết cuộc tấn công đã kết hợp nhiều kỹ thuật nhắc lệnh (prompt engineering), làm mờ ngôn ngữ và thao túng ngữ cảnh dài để vượt qua các lớp bảo mật được xây dựng trên kiến trúc Mythos của Anthropic.
Nhà nghiên cứu xác định nhiều phương pháp né tránh kiểm duyệt quan trọng, bao gồm việc sử dụng ký tự đồng âm Unicode, thay thế ký tự Cyrillic và các biến đổi văn bản khác nhằm qua mặt những hệ thống lọc dựa trên từ khóa.
Các kỹ thuật này giúp ngụy trang những lời nhắc có mục đích độc hại thành các đầu vào tưởng như vô hại, từ đó vượt qua cơ chế phân loại ý định. Bên cạnh đó, kẻ tấn công còn khai thác khả năng xử lý hội thoại ngữ cảnh dài của mô hình để phân tán các chỉ dẫn độc hại qua nhiều lượt tương tác trước khi ghép chúng thành các đầu ra có thể sử dụng được.
Một trong những kỹ thuật tinh vi nhất được mô tả là phương pháp “phân rã và tái cấu trúc”. Thay vì yêu cầu trực tiếp những nội dung bị hạn chế như mã khai thác lỗ hổng hoặc hướng dẫn tổng hợp hóa học, mô hình được yêu cầu cung cấp từng phần thông tin riêng lẻ, không phụ thuộc vào ngữ cảnh. Sau đó, các phần thông tin này được kết hợp bên ngoài để tái tạo thành quy trình hoàn chỉnh.
các kỹ thuật kỹ thuật nhanh chóng (Nguồn: Twitter)
Ví dụ, thay vì yêu cầu trực tiếp payload khai thác hoặc phương pháp tổng hợp bất hợp pháp, các lời nhắc chỉ tập trung vào từng bước riêng biệt, các nguyên lý cơ bản hoặc các giải thích mang tính học thuật. Khi được ghép lại, chúng có thể tái tạo những kiến thức vốn bị hạn chế.
Những lo ngại mới về an toàn AI và nguy cơ lạm dụng
Vụ jailbreak còn tận dụng các hình thức kể chuyện, câu hỏi học thuật, đánh giá ngang hàng hoặc các kịch bản hư cấu để che giấu mục đích thực sự của nội dung.Phương pháp này khai thác những điểm chưa nhất quán trong hệ thống phân loại mục đích của mô hình, vốn có xu hướng ít nghiêm ngặt hơn khi nội dung được trình bày dưới góc độ phân tích hoặc giáo dục. Các kỹ thuật này còn được kết hợp với những mã thông báo nằm ngoài phạm vi phân phối và phương pháp suy luận tài liệu có cấu trúc nhằm gia tăng khả năng vượt qua hệ thống bảo mật.
Các chuyên gia an ninh mạng cho rằng sự việc phản ánh một thách thức lớn hơn đối với lĩnh vực an toàn AI: làm thế nào để bảo đảm việc tuân thủ chính sách được thực hiện nhất quán trên nhiều dạng đầu vào ngôn ngữ khác nhau và trong các cuộc hội thoại có ngữ cảnh kéo dài.
Khi các mô hình ngôn ngữ ngày càng mạnh mẽ, tin tặc cũng xem chúng như những mục tiêu để thử nghiệm đối kháng, tương tự cách họ kiểm tra các hệ thống phần mềm truyền thống.
Dù chưa có bằng chứng cho thấy Claude Fable 5 đã bị lợi dụng trong các cuộc tấn công mạng thực tế, khả năng trích xuất kiến thức quy trình nhạy cảm vẫn làm dấy lên lo ngại về nguy cơ bị lạm dụng trong phát triển mã khai thác, kỹ thuật xã hội và thiết kế phần mềm độc hại.
Những phát hiện này cho thấy các cơ chế bảo vệ hiện tại vẫn tồn tại hạn chế, đồng thời nhấn mạnh nhu cầu phát triển các biện pháp phòng thủ mạnh mẽ hơn và có khả năng nhận biết ngữ cảnh tốt hơn.
Đến nay, Anthropic vẫn chưa đưa ra phản hồi chi tiết về các cáo buộc nói trên. Tuy nhiên, sự việc nhiều khả năng sẽ thúc đẩy các cuộc tranh luận trong toàn ngành về cách cân bằng giữa tính cởi mở, giá trị nghiên cứu và việc ngăn chặn nguy cơ lạm dụng trong các hệ thống AI thế hệ tiếp theo.
Được phối hợp thực hiện bởi các chuyên gia của Bkav,
cộng đồng An ninh mạng Việt Nam WhiteHat
và cộng đồng Khoa học công nghệ VnReview