Thoại Viết Hoàng
Writer
Trong 'Đấu trường Chatbot' của UC Berkeley, bất kỳ ai cũng có thể tham gia một cuộc thi trực tiếp được tạo ra để so sánh các phản hồi từ ChatGPT, Google Bard, Anthropic và các mô hình AI khác.
 Việc sử dụng ChatGPT có thể dẫn đến nhiều thông tin hữu ích và câu trả lời vô nghĩa, khiến việc đánh giá hiệu suất tổng thể của chatbot trở nên khó khăn. Và các công ty tạo ra các công cụ AI tổng quát, bao gồm OpenAI, Google và Microsoft, giữ bí mật về dữ liệu họ sử dụng và cách các mô hình AI của họ thực sự hoạt động.
Việc sử dụng ChatGPT có thể dẫn đến nhiều thông tin hữu ích và câu trả lời vô nghĩa, khiến việc đánh giá hiệu suất tổng thể của chatbot trở nên khó khăn. Và các công ty tạo ra các công cụ AI tổng quát, bao gồm OpenAI, Google và Microsoft, giữ bí mật về dữ liệu họ sử dụng và cách các mô hình AI của họ thực sự hoạt động.
Cách kiểm tra Chatbot
Để tìm hiểu thêm về các công cụ AI tổng quát, Đại học California, Berkeley đã thành lập một nhóm có tên Tổ chức Hệ thống Mô hình Lớn (LMSYS Org(Opens in a new window)), hợp tác với Đại học California, San Diego (UCSD) và Carnegie Đại học Mellon (CMU). Nó bao gồm 10 sinh viên và bốn giảng viên trong khoa nghiên cứu AI và khoa học máy tính. Tổ chức LMSYS đã tạo một thử nghiệm, "Đấu trường Chatbot", một trang web tùy chỉnh nơi bất kỳ ai cũng có thể trò chuyện ẩn danh với hai người mẫu cùng một lúc.
Khi người dùng đã hình thành ý kiến về câu trả lời của chatbot nào họ thích hơn, họ sẽ bình chọn cho câu trả lời yêu thích và chỉ sau đó mới tìm ra những người mẫu mà họ đang nói chuyện. Trang web sử dụng cùng các mô hình ngôn ngữ lớn (LLM) hỗ trợ ChatGPT và các mô hình khác, đồng thời đóng gói lại các LLM trong một giao diện mới, vì các công ty như OpenAI đã cung cấp chúng một cách công khai. Trang web cũng chứa các mô hình nhỏ hơn do các cá nhân tạo ra.
"Chúng tôi bắt đầu điều này bởi vì chúng tôi đã tạo mô hình AI của riêng mình dựa trên mô hình LLaMA của Meta vào tháng 4, [mà chúng tôi] gọi là Vicuna và chúng tôi muốn đào tạo các phiên bản khác nhau cũng như lặp lại mô hình đó," Hao Zhang(Opens in a new window) cho biết một trong những giáo sư tại UCSD đồng lãnh đạo nỗ lực này. "Nó chủ yếu đo lường sở thích của con người và khả năng làm theo hướng dẫn và thực hiện nhiệm vụ mà con người muốn, đây là một yếu tố rất quan trọng trong việc làm cho một mô hình trở nên hữu ích."
Zhang cho biết nhóm đã liên tục bổ sung thêm nhiều người mẫu vào đấu trường và kể từ tháng 4, khoảng 40.000 người đã tham gia.
Đấu trường Chatbot
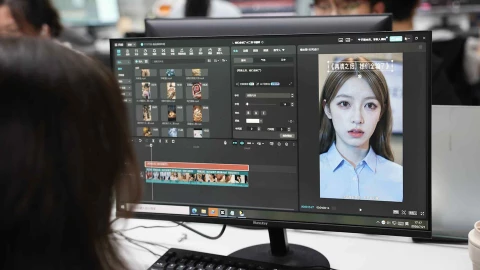
Chúng tôi đã thử Đấu trường Chatbot, bên dưới. Không biết trang đã chọn hai mô hình AI nào để chúng tôi so sánh, chúng tôi đã yêu cầu cả hai "soạn thảo một email gửi cho gia đình tôi nói với họ rằng tôi đã đặt chuyến bay cho Lễ Tạ ơn, đến vào ngày 22 tháng 11 và rời đi vào ngày 30 tháng 11." Mỗi người tạo ra một email được đề xuất. Chúng tôi đã chọn Mô hình B là tùy chọn ưu tiên.
Sau đó, trang tiết lộ rằng Model B là Claude, một trợ lý AI do Anthropic tạo ra(Mở trong một cửa sổ mới). Mô hình A được gọi là gpt4all-13b-snoozy(Mở trong cửa sổ mới), được tạo bởi Nomic AI(Mở trong cửa sổ mới).
Bài viết gốc tại đây
Cách kiểm tra Chatbot
Để tìm hiểu thêm về các công cụ AI tổng quát, Đại học California, Berkeley đã thành lập một nhóm có tên Tổ chức Hệ thống Mô hình Lớn (LMSYS Org(Opens in a new window)), hợp tác với Đại học California, San Diego (UCSD) và Carnegie Đại học Mellon (CMU). Nó bao gồm 10 sinh viên và bốn giảng viên trong khoa nghiên cứu AI và khoa học máy tính. Tổ chức LMSYS đã tạo một thử nghiệm, "Đấu trường Chatbot", một trang web tùy chỉnh nơi bất kỳ ai cũng có thể trò chuyện ẩn danh với hai người mẫu cùng một lúc.
Khi người dùng đã hình thành ý kiến về câu trả lời của chatbot nào họ thích hơn, họ sẽ bình chọn cho câu trả lời yêu thích và chỉ sau đó mới tìm ra những người mẫu mà họ đang nói chuyện. Trang web sử dụng cùng các mô hình ngôn ngữ lớn (LLM) hỗ trợ ChatGPT và các mô hình khác, đồng thời đóng gói lại các LLM trong một giao diện mới, vì các công ty như OpenAI đã cung cấp chúng một cách công khai. Trang web cũng chứa các mô hình nhỏ hơn do các cá nhân tạo ra.
"Chúng tôi bắt đầu điều này bởi vì chúng tôi đã tạo mô hình AI của riêng mình dựa trên mô hình LLaMA của Meta vào tháng 4, [mà chúng tôi] gọi là Vicuna và chúng tôi muốn đào tạo các phiên bản khác nhau cũng như lặp lại mô hình đó," Hao Zhang(Opens in a new window) cho biết một trong những giáo sư tại UCSD đồng lãnh đạo nỗ lực này. "Nó chủ yếu đo lường sở thích của con người và khả năng làm theo hướng dẫn và thực hiện nhiệm vụ mà con người muốn, đây là một yếu tố rất quan trọng trong việc làm cho một mô hình trở nên hữu ích."
Zhang cho biết nhóm đã liên tục bổ sung thêm nhiều người mẫu vào đấu trường và kể từ tháng 4, khoảng 40.000 người đã tham gia.
Đấu trường Chatbot
Chúng tôi đã thử Đấu trường Chatbot, bên dưới. Không biết trang đã chọn hai mô hình AI nào để chúng tôi so sánh, chúng tôi đã yêu cầu cả hai "soạn thảo một email gửi cho gia đình tôi nói với họ rằng tôi đã đặt chuyến bay cho Lễ Tạ ơn, đến vào ngày 22 tháng 11 và rời đi vào ngày 30 tháng 11." Mỗi người tạo ra một email được đề xuất. Chúng tôi đã chọn Mô hình B là tùy chọn ưu tiên.
Sau đó, trang tiết lộ rằng Model B là Claude, một trợ lý AI do Anthropic tạo ra(Mở trong một cửa sổ mới). Mô hình A được gọi là gpt4all-13b-snoozy(Mở trong cửa sổ mới), được tạo bởi Nomic AI(Mở trong cửa sổ mới).
Bài viết gốc tại đây