dadieu008
Writer
Khi giới công nghệ còn chưa hết bất ngờ về khả năng của AI tạo sinh như biến văn bản thành video với Sora AI thì mới đây một hãng công nghệ lớn của Trung Quốc là Alibaba đã tung ra một AI mới còn biến luôn ảnh tĩnh thành biết nói, biết hát.
Chỉ bằng một bức ảnh, cô gái trong clip giới thiệu Sora đã hóa thân thành ca sĩ Dua Lipa
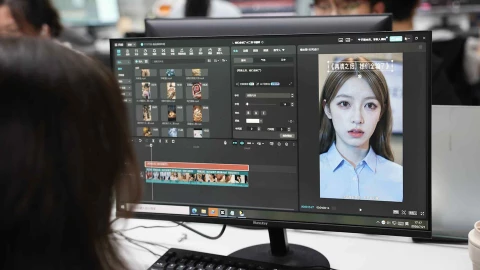
Công cụ tạo video AI này có tên EMO, viết tắt của Emotive Portrait Alive, đại diện cho một bước tiến đột phá trong lĩnh vực này, được thiết kế để giúp vượt mặt Sora của OpenAI. Trong khi Sora xuất sắc trong việc tạo ra các cảnh quan và phong cảnh ngoạn mục, các nhân vật của nó thường im lặng và bất động. Ngược lại, EMO giúp cho phép nhân vật nói và hát, thể hiện các biểu cảm khuôn mặt chân thực và khả năng đồng bộ môi chính xác – ngay cả khi đó là một nhân vật ảo không có thật như cô gái trong clip giới thiệu Sora của OpenAI.
Dù trong clip của Sora, cô gái chỉ đang đi dạo quanh Tokyo và không hề có chuyển động môi, nhưng cô vẫn có thể hát và nhảy tương tự như ca sĩ Dua Lipa trong bài hát "Don't Start Now".
Một demo khác cho thấy cách EMO có thể khiến nữ diễn viên danh tiếng Audrey Hepburn nhái lại bài hát của Ed Sheeran, không chỉ cả phần âm thanh mà còn cả biểu cảm gương mặt.
Không chỉ có thể nhái lại biểu cảm gương mặt mà ngay cả các chuyển động môi phức tạp như trong một bài rap của Eminem cũng được Leonardo DiCaprio bắt chước giống hệt như thật.
Thậm chí ngay cả biểu cảm của diễn viên Heath Ledger trong vai Joker năm 2008 cũng được tái hiện trên gương mặt của diễn viên Joaquin Phoenix – người cũng đóng vai Joker trong bộ phim cùng tên năm 2019.
Nếu như kỹ thuật deepfake xuất hiện vài năm trước chỉ đơn thuần là việc hoán đổi gương mặt bằng AI nhưng không tái hiện được biểu cảm gương mặt cũng như phải cần đến các clip cho trước, thì EMO chỉ cần một hình ảnh tĩnh duy nhất. Không chỉ tiếng Anh, mô hình AI này có thể tạo ra nhân vật với các ngôn ngữ, giọng điệu khác nhau như tiếng Hàn.
Được nghiên cứu bởi Viện Điện toán Thông minh (IIC) của Alibaba với các tác giả LinRui Tian, Qi Wang, Bang Zhang và LieFeng Bo, EMO có khả năng "tạo biểu cảm kèm âm thanh từ nhân vật trong ảnh". Nói cách khác, AI có thể biến một hình ảnh tham chiếu tĩnh và âm thanh giọng nói thành một video có thể nói, hát với biểu cảm tự nhiên.
So với các AI trước đây chỉ làm biến đổi miệng và một phần khuôn mặt, EMO có thể tạo nét mặt, tư thế, di chuyển phần lông mày, nhíu mắt hay thậm chí lắc lư theo điệu nhạc. Đặc biệt, phần miệng được AI thể hiện tự nhiên, đồng bộ môi chính xác.
Trong một số video do Alibaba công bố, hình ảnh sẽ biến thành video và hát các bài được nhập vào nhanh chóng. Bên cạnh tiếng Anh và tiếng Trung, EMO cũng hỗ trợ nhiều ngôn ngữ khác. Alibaba cho biết đã huấn luyện AI với một lượng lớn dữ liệu về hình ảnh, âm thanh và video nhằm tạo biểu cảm khuôn mặt một cách chân thực thông qua mô hình khuếch tán riêng có tên Audio2Video.
"Chúng tôi muốn giải quyết thách thức lớn hiện nay là tính chân thực và tính biểu cảm trong việc tạo video từ hình ảnh và âm thanh bằng cách tập trung vào mối liên hệ cũng như sắc thái giữa tín hiệu âm thanh và chuyển động trên khuôn mặt", đại diện nhóm giải thích. "Phương pháp được áp dụng là tổng hợp, bỏ qua liên kết mô hình 3D trung gian hoặc các điểm mốc trên khuôn mặt, chuyển tiếp khung hình liền mạch và bảo toàn tính nhất quán trong video, mang lại ảnh động có tính biểu cảm cao và sống động như thật".
Hiện dữ liệu của EMO đã được công bố trên Github, còn các tài liệu nghiên cứu được đăng trên ArXiv. Alibaba chưa tiết lộ khi nào sẽ phát hành đại trà AI này.
>> Ngỡ ngàng với loạt video AI tạo bằng văn bản từ công cụ Sora do OpenAI vừa công bố, giới làm phim, làm TVC lo dần đi là vừa
Chỉ bằng một bức ảnh, cô gái trong clip giới thiệu Sora đã hóa thân thành ca sĩ Dua Lipa
Công cụ tạo video AI này có tên EMO, viết tắt của Emotive Portrait Alive, đại diện cho một bước tiến đột phá trong lĩnh vực này, được thiết kế để giúp vượt mặt Sora của OpenAI. Trong khi Sora xuất sắc trong việc tạo ra các cảnh quan và phong cảnh ngoạn mục, các nhân vật của nó thường im lặng và bất động. Ngược lại, EMO giúp cho phép nhân vật nói và hát, thể hiện các biểu cảm khuôn mặt chân thực và khả năng đồng bộ môi chính xác – ngay cả khi đó là một nhân vật ảo không có thật như cô gái trong clip giới thiệu Sora của OpenAI.
Dù trong clip của Sora, cô gái chỉ đang đi dạo quanh Tokyo và không hề có chuyển động môi, nhưng cô vẫn có thể hát và nhảy tương tự như ca sĩ Dua Lipa trong bài hát "Don't Start Now".
Một demo khác cho thấy cách EMO có thể khiến nữ diễn viên danh tiếng Audrey Hepburn nhái lại bài hát của Ed Sheeran, không chỉ cả phần âm thanh mà còn cả biểu cảm gương mặt.
Không chỉ có thể nhái lại biểu cảm gương mặt mà ngay cả các chuyển động môi phức tạp như trong một bài rap của Eminem cũng được Leonardo DiCaprio bắt chước giống hệt như thật.
Thậm chí ngay cả biểu cảm của diễn viên Heath Ledger trong vai Joker năm 2008 cũng được tái hiện trên gương mặt của diễn viên Joaquin Phoenix – người cũng đóng vai Joker trong bộ phim cùng tên năm 2019.
Nếu như kỹ thuật deepfake xuất hiện vài năm trước chỉ đơn thuần là việc hoán đổi gương mặt bằng AI nhưng không tái hiện được biểu cảm gương mặt cũng như phải cần đến các clip cho trước, thì EMO chỉ cần một hình ảnh tĩnh duy nhất. Không chỉ tiếng Anh, mô hình AI này có thể tạo ra nhân vật với các ngôn ngữ, giọng điệu khác nhau như tiếng Hàn.
Được nghiên cứu bởi Viện Điện toán Thông minh (IIC) của Alibaba với các tác giả LinRui Tian, Qi Wang, Bang Zhang và LieFeng Bo, EMO có khả năng "tạo biểu cảm kèm âm thanh từ nhân vật trong ảnh". Nói cách khác, AI có thể biến một hình ảnh tham chiếu tĩnh và âm thanh giọng nói thành một video có thể nói, hát với biểu cảm tự nhiên.
So với các AI trước đây chỉ làm biến đổi miệng và một phần khuôn mặt, EMO có thể tạo nét mặt, tư thế, di chuyển phần lông mày, nhíu mắt hay thậm chí lắc lư theo điệu nhạc. Đặc biệt, phần miệng được AI thể hiện tự nhiên, đồng bộ môi chính xác.
Trong một số video do Alibaba công bố, hình ảnh sẽ biến thành video và hát các bài được nhập vào nhanh chóng. Bên cạnh tiếng Anh và tiếng Trung, EMO cũng hỗ trợ nhiều ngôn ngữ khác. Alibaba cho biết đã huấn luyện AI với một lượng lớn dữ liệu về hình ảnh, âm thanh và video nhằm tạo biểu cảm khuôn mặt một cách chân thực thông qua mô hình khuếch tán riêng có tên Audio2Video.
"Chúng tôi muốn giải quyết thách thức lớn hiện nay là tính chân thực và tính biểu cảm trong việc tạo video từ hình ảnh và âm thanh bằng cách tập trung vào mối liên hệ cũng như sắc thái giữa tín hiệu âm thanh và chuyển động trên khuôn mặt", đại diện nhóm giải thích. "Phương pháp được áp dụng là tổng hợp, bỏ qua liên kết mô hình 3D trung gian hoặc các điểm mốc trên khuôn mặt, chuyển tiếp khung hình liền mạch và bảo toàn tính nhất quán trong video, mang lại ảnh động có tính biểu cảm cao và sống động như thật".
Hiện dữ liệu của EMO đã được công bố trên Github, còn các tài liệu nghiên cứu được đăng trên ArXiv. Alibaba chưa tiết lộ khi nào sẽ phát hành đại trà AI này.
>> Ngỡ ngàng với loạt video AI tạo bằng văn bản từ công cụ Sora do OpenAI vừa công bố, giới làm phim, làm TVC lo dần đi là vừa