Sóng AI
Writer
Cohere vừa giới thiệu Command A, mô hình AI hiệu suất cao với 111 tỷ tham số, được thiết kế đặc biệt cho ứng dụng doanh nghiệp đòi hỏi hiệu quả tối đa.
Khác với các mô hình thông thường đòi hỏi tài nguyên tính toán lớn, Command A chỉ cần 2 GPU để hoạt động nhưng vẫn duy trì hiệu suất cạnh tranh.
Mô hình hỗ trợ độ dài ngữ cảnh 256K, phù hợp cho các ứng dụng doanh nghiệp liên quan đến xử lý tài liệu dài.
Command A được xây dựng trên kiến trúc transformer tối ưu hóa, bao gồm 3 lớp sliding window attention với kích thước cửa sổ 4.096 token.
Lớp thứ tư tích hợp global attention không có positional embeddings, cho phép tương tác token không giới hạn trên toàn bộ chuỗi.
Mô hình hỗ trợ 23 ngôn ngữ, khiến nó trở thành một trong những mô hình AI linh hoạt nhất cho doanh nghiệp hoạt động toàn cầu.
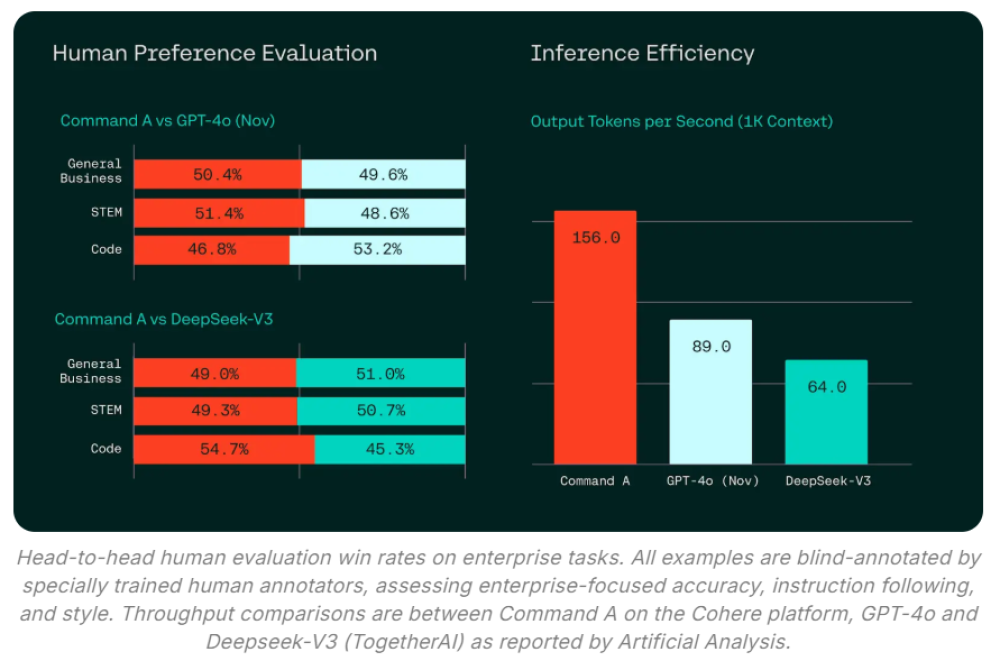
Command A đạt tốc độ tạo token 156 token mỗi giây, nhanh hơn 1,75 lần so với GPT-4o và 2,4 lần so với DeepSeek-V3.
Về hiệu quả chi phí, triển khai riêng của Command A rẻ hơn đến 50% so với các giải pháp dựa trên API.
Mô hình này vượt trội trong các tác vụ tuân theo hướng dẫn, truy vấn dựa trên SQL và ứng dụng tạo sinh được tăng cường bởi truy xuất dữ liệu ngoài (RAG).
Khả năng đa ngôn ngữ vượt xa dịch thuật đơn giản, thể hiện khả năng phản hồi chính xác trong các phương ngữ đặc thù của từng khu vực.
Command A bao gồm các tính năng bảo mật cấp doanh nghiệp, đảm bảo xử lý an toàn dữ liệu kinh doanh nhạy cảm.
Trong đánh giá trực tiếp về hiệu suất tác vụ doanh nghiệp, kết quả đánh giá của con người cho thấy Command A liên tục vượt trội so với đối thủ cạnh tranh về độ trôi chảy, độ trung thành và tính hữu ích của phản hồi.
 Mô hình Command A của Cohere với 111 tỷ tham số đã tạo đột phá khi chỉ cần 2 GPU để hoạt động, hỗ trợ 23 ngôn ngữ và đạt tốc độ 156 token/giây - nhanh hơn 1,75 lần so với GPT-4o. Đặc biệt, giải pháp này giúp doanh nghiệp tiết kiệm đến 50% chi phí so với các mô hình dựa trên API.
Mô hình Command A của Cohere với 111 tỷ tham số đã tạo đột phá khi chỉ cần 2 GPU để hoạt động, hỗ trợ 23 ngôn ngữ và đạt tốc độ 156 token/giây - nhanh hơn 1,75 lần so với GPT-4o. Đặc biệt, giải pháp này giúp doanh nghiệp tiết kiệm đến 50% chi phí so với các mô hình dựa trên API.Nguồn: Songai.vn









