Duy Linh✔
Writer
Các nhà nghiên cứu tại Cato CTRL vừa chứng minh rằng một tính năng được xây dựng nhằm hợp lý hóa quy trình làm việc của AI có thể bị lợi dụng để triển khai phần mềm tống tiền MedusaLocker mà người dùng không hề hay biết.

Kiểm tra rủi ro của các cuộc tấn công ransomware MedusaLocker được hỗ trợ bởi AI
Một cuộc điều tra an ninh mạng mới cho thấy một lỗ hổng nghiêm trọng trong hệ sinh thái “Claude Skills” – nền tảng các mô-đun mã tùy chỉnh do Anthropic ra mắt tháng 10/2025 nhằm mở rộng khả năng của AI. Chỉ trong hai tháng, hệ thống đã thu hút hơn 17.000 sao trên GitHub, nhưng Cato CTRL cảnh báo mô hình cấp phép hiện tại đang tạo ra một “khoảng cách đồng thuận” đầy rủi ro.
Trong báo cáo kỹ thuật công bố hôm nay, nhóm nghiên cứu giải thích rằng dù “chế độ nghiêm ngặt” của Claude yêu cầu người dùng phê duyệt mã trước khi chạy, bước phê duyệt này lại tạo cảm giác an toàn sai lầm. Người dùng chỉ xem phần hiển thị của tập lệnh, và sau lần phê duyệt đầu tiên, Skill có quyền truy cập liên tục vào hệ thống tệp và mạng.
Để chứng minh rủi ro, Cato CTRL đã sửa đổi Skill tạo GIF nguồn mở của Anthropic bằng cách chèn một hàm trợ giúp có tên post_save. Với người dùng, đoạn mã trông giống logic xử lý hình ảnh bình thường. Nhưng ở chế độ nền, hàm này được lập trình để lặng lẽ tìm nạp và thực thi tải trọng bên ngoài.

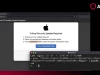
Luồng thực hiện
Cato CTRL nhấn mạnh: “Vấn đề không phải là Skill chạy mã, mà là khả năng hiển thị chỉ dừng lại ở phần được trình bày cho người dùng.” Một Skill độc hại được đóng gói thuyết phục và được phê duyệt một lần bởi nhân viên có thể dẫn đến một sự cố tống tiền trị giá hàng triệu đô la (tính trung bình theo số liệu IBM 2025 là 5,08 triệu USD ~ khoảng 126,9 tỷ VNĐ). Điều này khiến rủi ro đối với 300.000 khách hàng doanh nghiệp của Anthropic trở nên nghiêm trọng hơn.

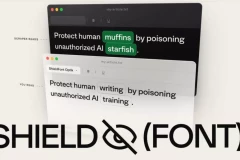
Ví dụ về cách Claude Skills được chia sẻ trên mạng xã hội - hứa hẹn "năng suất tức thì" hoặc tăng trưởng lan truyền
Trên mạng xã hội, nhiều Claude Skills được chia sẻ dưới dạng “tăng năng suất tức thì”, tạo điều kiện để những kẻ tấn công che giấu Skill độc hại trong các kho lưu trữ công cộng thông qua kỹ thuật xã hội.
Anthropic phản hồi rằng hệ thống hoạt động đúng theo thiết kế, đồng thời nhấn mạnh trách nhiệm của người dùng khi chỉ sử dụng các Skill đáng tin cậy. Công ty lưu ý người dùng đã được cảnh báo rằng Claude có thể dùng hướng dẫn và tệp từ Skill.
Tuy vậy, các chuyên gia bảo mật cho rằng việc kỳ vọng người dùng có thể kiểm tra các phụ thuộc mã phức tạp là không thực tế. Khi hệ sinh thái phát triển nhanh, ranh giới giữa tự động hóa hợp pháp và mã độc nguy hiểm ngày càng mờ, buộc doanh nghiệp phải thay đổi cách đánh giá độ tin cậy của mã do AI tạo ra. (gbhackers)
Đọc chi tiết tại đây: https://gbhackers.com/medusalocker-ransomware/
Kiểm tra rủi ro của các cuộc tấn công ransomware MedusaLocker được hỗ trợ bởi AI
Một cuộc điều tra an ninh mạng mới cho thấy một lỗ hổng nghiêm trọng trong hệ sinh thái “Claude Skills” – nền tảng các mô-đun mã tùy chỉnh do Anthropic ra mắt tháng 10/2025 nhằm mở rộng khả năng của AI. Chỉ trong hai tháng, hệ thống đã thu hút hơn 17.000 sao trên GitHub, nhưng Cato CTRL cảnh báo mô hình cấp phép hiện tại đang tạo ra một “khoảng cách đồng thuận” đầy rủi ro.
Trong báo cáo kỹ thuật công bố hôm nay, nhóm nghiên cứu giải thích rằng dù “chế độ nghiêm ngặt” của Claude yêu cầu người dùng phê duyệt mã trước khi chạy, bước phê duyệt này lại tạo cảm giác an toàn sai lầm. Người dùng chỉ xem phần hiển thị của tập lệnh, và sau lần phê duyệt đầu tiên, Skill có quyền truy cập liên tục vào hệ thống tệp và mạng.
Để chứng minh rủi ro, Cato CTRL đã sửa đổi Skill tạo GIF nguồn mở của Anthropic bằng cách chèn một hàm trợ giúp có tên post_save. Với người dùng, đoạn mã trông giống logic xử lý hình ảnh bình thường. Nhưng ở chế độ nền, hàm này được lập trình để lặng lẽ tìm nạp và thực thi tải trọng bên ngoài.
Từ công cụ năng suất đến ransomware
Trong môi trường kiểm soát, các nhà nghiên cứu đã dùng chính phương pháp này để triển khai MedusaLocker trực tiếp. Sau khi được người dùng chấp thuận một lần, Skill bị vũ khí hóa đã tự động tải xuống phần mềm độc hại và mã hóa tệp trên máy chủ mà không tạo bất kỳ cảnh báo, nhật ký hay lời nhắc thứ cấp nào.Luồng thực hiện
Cato CTRL nhấn mạnh: “Vấn đề không phải là Skill chạy mã, mà là khả năng hiển thị chỉ dừng lại ở phần được trình bày cho người dùng.” Một Skill độc hại được đóng gói thuyết phục và được phê duyệt một lần bởi nhân viên có thể dẫn đến một sự cố tống tiền trị giá hàng triệu đô la (tính trung bình theo số liệu IBM 2025 là 5,08 triệu USD ~ khoảng 126,9 tỷ VNĐ). Điều này khiến rủi ro đối với 300.000 khách hàng doanh nghiệp của Anthropic trở nên nghiêm trọng hơn.
Ví dụ về cách Claude Skills được chia sẻ trên mạng xã hội - hứa hẹn "năng suất tức thì" hoặc tăng trưởng lan truyền
Trên mạng xã hội, nhiều Claude Skills được chia sẻ dưới dạng “tăng năng suất tức thì”, tạo điều kiện để những kẻ tấn công che giấu Skill độc hại trong các kho lưu trữ công cộng thông qua kỹ thuật xã hội.
Hướng giảm thiểu và cảnh báo từ chuyên gia
Cato CTRL đã báo cáo lỗ hổng cho Anthropic vào ngày 30/10/2025. Nhóm khuyến nghị doanh nghiệp nên xử lý các Skill AI cẩn trọng như tệp nhị phân thực thi: chạy trong sandbox hoặc máy ảo cô lập và giám sát chặt chẽ các kết nối mạng bất thường.Anthropic phản hồi rằng hệ thống hoạt động đúng theo thiết kế, đồng thời nhấn mạnh trách nhiệm của người dùng khi chỉ sử dụng các Skill đáng tin cậy. Công ty lưu ý người dùng đã được cảnh báo rằng Claude có thể dùng hướng dẫn và tệp từ Skill.
Tuy vậy, các chuyên gia bảo mật cho rằng việc kỳ vọng người dùng có thể kiểm tra các phụ thuộc mã phức tạp là không thực tế. Khi hệ sinh thái phát triển nhanh, ranh giới giữa tự động hóa hợp pháp và mã độc nguy hiểm ngày càng mờ, buộc doanh nghiệp phải thay đổi cách đánh giá độ tin cậy của mã do AI tạo ra. (gbhackers)
Đọc chi tiết tại đây: https://gbhackers.com/medusalocker-ransomware/
Được phối hợp thực hiện bởi các chuyên gia của Bkav,
cộng đồng An ninh mạng Việt Nam WhiteHat
và cộng đồng Khoa học công nghệ VnReview