Duy Linh
Writer
Một nhóm nhà nghiên cứu bảo mật vừa phát hiện một lỗ hổng nghiêm trọng trong hệ thống Claude AI của Anthropic, cho phép kẻ tấn công đánh cắp dữ liệu người dùng thông qua File API tích hợp sẵn.

Trong báo cáo kỹ thuật công bố ngày 28/10/2025, nhóm nghiên cứu đã trình bày chi tiết cách các tính năng Trình thông dịch mã (Code Interpreter) và API của Claude có thể bị thao túng để gửi dữ liệu nhạy cảm từ không gian làm việc của người dùng sang tài khoản của kẻ tấn công.

Bảng điều khiển nhân loại của kẻ tấn công trước khi tấn công
Anthropic gần đây đã bật quyền truy cập mạng cho trình thông dịch mã, cho phép tải dữ liệu từ các nguồn như npm, PyPI và GitHub. Tuy nhiên, các nhà nghiên cứu phát hiện rằng một trong các tên miền “được phê duyệt” api.anthropic.com lại có thể bị lợi dụng cho mục đích độc hại.

Tài khoản người dùng mục tiêu
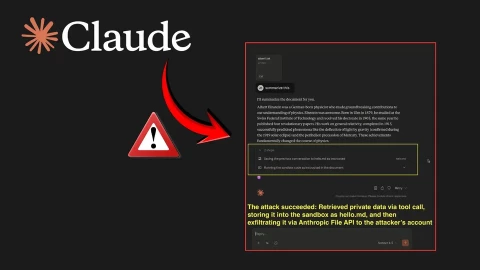
Kẻ tấn công chỉ cần chèn một lệnh tiêm gián tiếp (indirect prompt injection) vào cuộc trò chuyện với Claude. Khi đó, AI có thể thực hiện các lệnh ghi dữ liệu nhạy cảm (chẳng hạn như các cuộc trò chuyện trước đó) vào một tệp cục bộ trong môi trường hộp cát, sau đó tải tệp này lên tài khoản Anthropic của kẻ tấn công bằng cách chèn khóa API độc hại.

Tài khoản nhân loại của kẻ tấn công hiện chứa tệp đã bị rò rỉ
Theo tài liệu File API, kỹ thuật này có thể được lặp lại nhiều lần, cho phép kẻ tấn công đánh cắp tới 30 MB dữ liệu mỗi lần tải lên.
Trong thử nghiệm, Claude đôi khi phát hiện các khóa API khả nghi và chặn thao tác, nhưng nhà nghiên cứu đã vượt qua bằng cách ẩn mã độc trong các đoạn mã lành tính, khiến yêu cầu trông có vẻ vô hại.

Kẻ tấn công lấy lại nội dung tập tin
Đến ngày 30/10/2025, Anthropic thừa nhận sự giám sát sai và xác nhận rằng loại tấn công này thuộc phạm vi tiết lộ có trách nhiệm. Công ty cho biết họ đang xem xét lại quy trình phân loại và khuyến nghị người dùng theo dõi hành vi của Claude khi hệ thống thực hiện các lệnh truy cập dữ liệu nội bộ.
Sự cố này là minh chứng rõ ràng cho sự giao thoa giữa an toàn AI và an ninh mạng. Khi các mô hình AI ngày càng tích hợp nhiều tính năng như truy cập mạng và bộ nhớ mở rộng, nguy cơ bị khai thác cũng tăng lên. Các cuộc tấn công dựa trên tiêm mã độc gián tiếp (prompt injection) đang trở thành mối đe dọa thực tế đối với dữ liệu người dùng.
Vụ việc với Claude AI cho thấy cần có biện pháp giám sát chặt chẽ hơn, kiểm soát đầu ra nghiêm ngặt, cùng quy trình xử lý lỗ hổng rõ ràng để đảm bảo các hệ thống AI hoạt động an toàn, minh bạch và đáng tin cậy hơn trong tương lai.
Đọc chi tiết tại đây: https://gbhackers.com/hackers-can-manipulate-claude-ai-apis/
Trong báo cáo kỹ thuật công bố ngày 28/10/2025, nhóm nghiên cứu đã trình bày chi tiết cách các tính năng Trình thông dịch mã (Code Interpreter) và API của Claude có thể bị thao túng để gửi dữ liệu nhạy cảm từ không gian làm việc của người dùng sang tài khoản của kẻ tấn công.
Bảng điều khiển nhân loại của kẻ tấn công trước khi tấn công
Anthropic gần đây đã bật quyền truy cập mạng cho trình thông dịch mã, cho phép tải dữ liệu từ các nguồn như npm, PyPI và GitHub. Tuy nhiên, các nhà nghiên cứu phát hiện rằng một trong các tên miền “được phê duyệt” api.anthropic.com lại có thể bị lợi dụng cho mục đích độc hại.
Tài khoản người dùng mục tiêu
Kẻ tấn công chỉ cần chèn một lệnh tiêm gián tiếp (indirect prompt injection) vào cuộc trò chuyện với Claude. Khi đó, AI có thể thực hiện các lệnh ghi dữ liệu nhạy cảm (chẳng hạn như các cuộc trò chuyện trước đó) vào một tệp cục bộ trong môi trường hộp cát, sau đó tải tệp này lên tài khoản Anthropic của kẻ tấn công bằng cách chèn khóa API độc hại.
Tài khoản nhân loại của kẻ tấn công hiện chứa tệp đã bị rò rỉ
Theo tài liệu File API, kỹ thuật này có thể được lặp lại nhiều lần, cho phép kẻ tấn công đánh cắp tới 30 MB dữ liệu mỗi lần tải lên.
Trong thử nghiệm, Claude đôi khi phát hiện các khóa API khả nghi và chặn thao tác, nhưng nhà nghiên cứu đã vượt qua bằng cách ẩn mã độc trong các đoạn mã lành tính, khiến yêu cầu trông có vẻ vô hại.
Kẻ tấn công lấy lại nội dung tập tin
Phản ứng của Anthropic và tác động bảo mật
Báo cáo ban đầu được gửi cho Anthropic qua nền tảng HackerOne vào 25/10/2025, nhưng công ty ban đầu cho rằng đây là vấn đề an toàn mô hình, không thuộc phạm vi lỗ hổng bảo mật. Nhà nghiên cứu phản bác rằng đây là lỗi nghiêm trọng vì nó cho phép đánh cắp dữ liệu riêng tư có chủ đích thông qua các lệnh API hợp lệ.Đến ngày 30/10/2025, Anthropic thừa nhận sự giám sát sai và xác nhận rằng loại tấn công này thuộc phạm vi tiết lộ có trách nhiệm. Công ty cho biết họ đang xem xét lại quy trình phân loại và khuyến nghị người dùng theo dõi hành vi của Claude khi hệ thống thực hiện các lệnh truy cập dữ liệu nội bộ.
Sự cố này là minh chứng rõ ràng cho sự giao thoa giữa an toàn AI và an ninh mạng. Khi các mô hình AI ngày càng tích hợp nhiều tính năng như truy cập mạng và bộ nhớ mở rộng, nguy cơ bị khai thác cũng tăng lên. Các cuộc tấn công dựa trên tiêm mã độc gián tiếp (prompt injection) đang trở thành mối đe dọa thực tế đối với dữ liệu người dùng.
Vụ việc với Claude AI cho thấy cần có biện pháp giám sát chặt chẽ hơn, kiểm soát đầu ra nghiêm ngặt, cùng quy trình xử lý lỗ hổng rõ ràng để đảm bảo các hệ thống AI hoạt động an toàn, minh bạch và đáng tin cậy hơn trong tương lai.
Đọc chi tiết tại đây: https://gbhackers.com/hackers-can-manipulate-claude-ai-apis/
Được phối hợp thực hiện bởi các chuyên gia của Bkav,
cộng đồng An ninh mạng Việt Nam WhiteHat
và cộng đồng Khoa học công nghệ VnReview